

For many people in the IT community, 2022 got off to a bad start after a bug in on-premises versions of Microsoft Exchange Server caused emails to become stuck en route due to a failed date check. Put simply, a bug subsequently dubbed Y2K22 (named in the style of the Y2K bug that spooked the world starting about a quarter century ago) caused the software to be unable to handle the date format for the year 2022. Microsoft’s fix? Set the date on malware detection updates back to the fictional December 33rd, 2021, giving the date value enough “breathing space” before reaching the highest value the underlying integer type can hold.
Yet the real lesson for developers is that implementing your own date-handling code is too fraught with the risk of making such mistakes and coming up with strange fixes that would use fictional dates. So unless you are writing those routines for an operating system, a compiler, etc., you should always use standard date APIs.
Back in 2015, a bug of similar ilk was found to affect the software of Boeing’s 787 Dreamliner jet. Had it not been spotted and squashed in time, the bug could have led to a total loss of all AC electrical power, even in midflight, on the aircraft after 248 days of continuous power. The solution to avoid pilots losing control of their airliner midair? Reboot your 787 before 248 days are up, or better, apply the patch.
So why did Microsoft need to pretend updates for its Exchange antimalware component were still from 2021? Why does a plane need to be turned off and back on just so it doesn’t crash? In both cases, the blame fell squarely on an integer overflow, a vulnerability that is a concern in all types of software, ranging from video games to GPS systems to aeronautics. In the 2021 CWE Top 25 Most Dangerous Software Weaknesses list, which looked at around 32,500 CVEs published in 2019 and 2020, integer overflow or wraparound ranked in twelfth place.
Are software developers so mathematically challenged that they can’t anticipate when they might be running out of numbers? The reality is more complex, in fact. Let’s look a little more deeply at how computers store and handle numbers to see how elusive an integer overflow can be.
What is an integer?
In mathematics, integers include positive numbers like 1, 2, and 3, the number 0, and negative numbers like −1, −2, and −3. Integers do not include fractions or decimals. That means the set of all integers can be represented with the following number line:

Commonly, a programming language has several integer variable types – each one stores a range of integer values depending on the number of bits that type uses on a particular machine. The more bits that an integer type consumes, the greater the values that can be stored therein.
Let’s consider the integer types in the C programming language, assuming bit sizes that we might expect on a typical x64 machine.
A char consumes 8 bits of memory, meaning that it can store the following values:
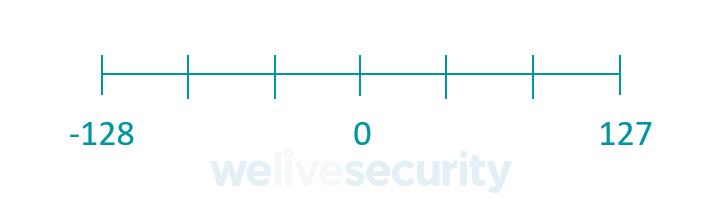
Notice that a char can only store values down to a minimum of -128 and up to a maximum of 127.
But there is another “mode” of the char integer type that only stores non-negative integers:

Integer types have both signed and unsigned modes. Signed types can store negative values, whereas unsigned types cannot.
The following table shows some of the principal integer types in the programming language C, their sizes on a typical x64 machine, and the range of values they can store:
Table 1. Integer types, their typical sizes and ranges for the Microsoft C++ (MSVC) compiler toolset
| Type | Size (bit width) | Range |
|---|---|---|
| char | 8 | signed: −128 to 127 |
| #rowspan# | unsigned: 0 to 255 | |
| short int | 16 | signed: −32,768 to 32,767 |
| #rowspan# | unsigned: 0 to 65,535 | |
| int | 32 | signed: −2,147,483,648 to 2,147,483,647 |
| #rowspan# | unsigned: 0 to 4,294,967,295 | |
| long long int | 64 | signed: −9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 |
| #rowspan# | unsigned: 0 to 18,446,744,073,709,551,615 |
What is an integer overflow?
An integer overflow or wraparound happens when an attempt is made to store a value that is too large for an integer type. The range of values that can be stored in an integer type is better represented as a circular number line that wraps around. The circular number line for a signed char can be represented as the following:
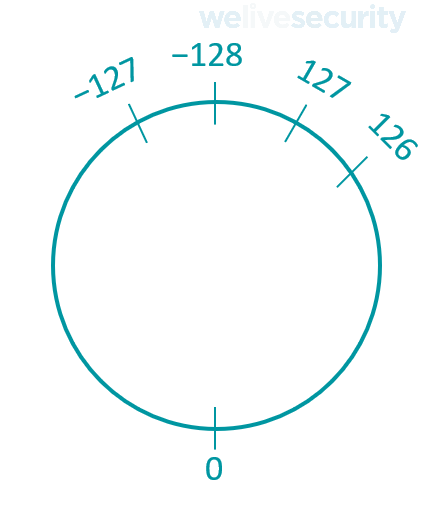
If an attempt is made to store a number greater than 127 in a signed char, the count wraps around to −128 and continues upwards, toward zero, from there. Thus, instead of what should be 128 the value −128 is stored, instead of 129 the value −127, and so on.
Looking at the problem in reverse, if an attempt is made to store a number less than -128 in a signed char, the count wraps around to 127 and continues downwards, toward zero, from there. Thus, instead of what should be −129 the value 127 is stored, instead of −129 the value 126, and so on. This is sometimes called an integer underflow.
Hunting down the elusive integer overflow
Thinking of an integer overflow as a circle of values that wrap around makes it fairly easy to understand. However, it’s when we get down to the nitty gritty of “casting” integer types and porting and compiling programs that we can better understand some of the challenges involved in avoiding integer overflows.
Watch your casts
Sometimes it is useful, or even required, to store a value in a different type than the one originally used – casting, or “type conversion”, allows programmers to do that. Although some casts are safe, others are not because they can lead to integer overflows. A cast is considered safe when the original value is guaranteed to be preserved.
It is safe to cast a value stored in a smaller (in terms of bit width) integer type to a larger integer type within the same mode – from a smaller unsigned type to a larger unsigned type and from a smaller signed type to a larger signed type. Thus, it is safe to cast from a signed char to a signed short int because a signed short int is large enough to store all the possible values that can be stored in a signed char:
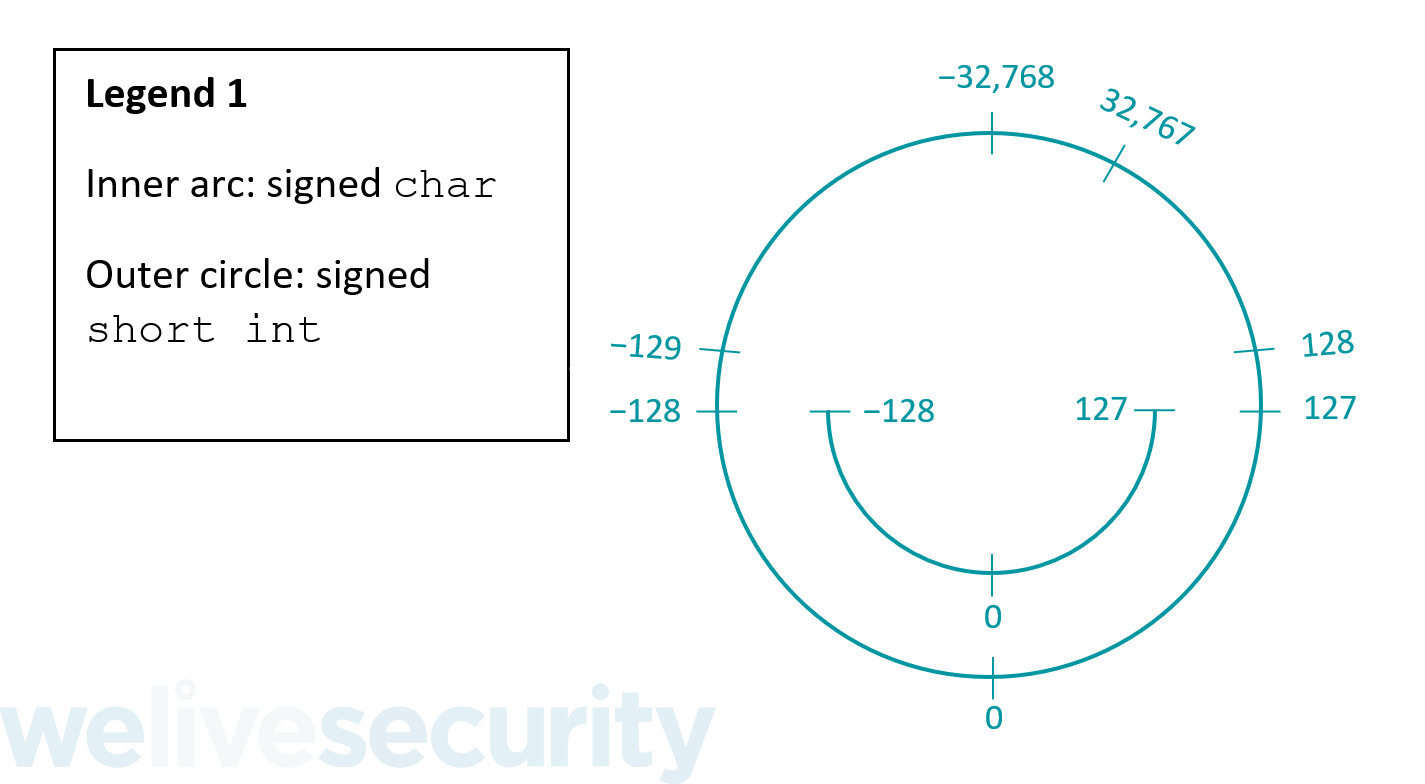
Casting between signed and unsigned integers is a red flag for integer overflows as the values cannot be guaranteed to remain the same. When casting from a signed type to an unsigned type (even if it’s larger) an integer overflow can happen because unsigned types cannot store negative values:

All the negative signed char values to the left of the red line in the image above from −128 to −1 will cause an integer overflow and become high positive values when cast to an unsigned type. −128 becomes 128, −127 becomes 129, and so on.
In reverse, when casting from an unsigned type to a signed type of the same size, an integer overflow can happen because the upper half of the positive values that can be stored in an unsigned type exceed the maximum value that can be stored in a signed type of that size.
All the high positive unsigned char values to the left of the red line in the above image from 128 to 255 will cause an integer overflow and become negative values when cast to a signed type of the same size. 128 becomes −128, 129 becomes −127, and so on.
Casting from an unsigned typed to a signed type of a larger size is more forgiving because it carries no risk of an integer overflow: all the values that can be stored in a smaller unsigned type can also be stored in a larger signed type.
Implicit upcasts: Beware of the “prejudice” for 32 bits
Although having the ability to explicitly cast integer types is useful, it is important to be aware of how compilers implicitly upcast the operands of operators (arithmetic, binary, Boolean, and unary). In many cases, these implicit upcasts help prevent integer overflows because they promote operands to larger-sized integer types before operating on them — indeed, the underlying hardware commonly requires operations to be done on operands of the same type and compilers will promote smaller-sized operands to larger ones to achieve this goal.
However, the rules for implicit upcasts favor 32-bit types, meaning that the consequences can at times be unexpected for the programmer. The rules follow a priority. First, if one or both of the operands is a 64-bit integer type (long long int), the other operand is upcast to 64 bits, if it is not already one, and the result is a 64-bit type. Second, if one or both of the operands is a 32-bit integer type (int), the other operand is upcast to a 32-bit type, if it is not already one, and the result is a 32-bit type.
Now here is the exception to this pattern that can easily trip up programmers. If one or both of the operands are 16-bit types (short int) or 8-bit types (char), the operands are upcast to 32 bits before the operation is performed and the result is a 32-bit type (int). The only operators that are an exception to this behavior are the pre- and postfix increment and decrement operators (++, --), which means that a 16-bit (short int) operand, for instance, is not upcast and the result is also 16 bits.
The “prejudiced” upcast of 8-bit and 16-bit operands to 32-bits is critical to understand when making checks to prevent integer overflows. If you think you are adding two char or two short int types, you are mistaken because they are implicitly upcast to int types and return an int result. With a 32-bit result being returned by the operation, it is necessary to downcast the result to 16 or 8 bits before checking for an integer overflow. Otherwise, there is a risk of not detecting an integer overflow because an int won’t overflow with the comparatively small values that a short int or a char might provide as operands.
Code portability issues I – different compilers
Creating different builds of a program that can run on different architectures is an important consideration at software design time. Not only can it be a headache to rewrite code that was poorly planned out for different builds, but it can also lead to integer overflows if care is not taken.
Compilers, which are used to build code for different target machines, are expected to support the standard of a programming language, but there are certain implementation details that are undefined and left to the decision of compiler developers. The sizes of integer types in C is one of those details with only a bare skeleton of guidance in the C language standard, meaning that not understanding the implementation details for your compiler and target machine is a recipe for possible disaster.
The number of bits consumed by each integer type described in Table 1 is the scheme used by the Microsoft C++ (MSVC) compiler toolset, which includes a C compiler, when targeting 32-bit, 64-bit, and ARM processors. However, different compilers that implement the C standard can use different schemes. Let’s consider an integer type called a long.
For the MSVC compiler, a long consumes 32 bits regardless of whether the build is for a 32-bit or 64-bit program. For the IBM XL C compiler, however, a long consumes 32 bits in a 32-bit build and 64 bits in a 64-bit build. It is critical to know the sizes and maximum and minimum values an integer type can hold in order to check for integer overflows correctly for all your builds.
Code portability issues II – different builds
Another portability issue to watch out for is in the use of size_t, which is an unsigned integer type, and ptrdiff_t, which is a signed integer type. These types consume 32 bits in a 32-bit build and 64 bits in a 64-bit build for the MSVC compiler. A piece of code that decides whether to branch based on a comparison in which one of the operands is of one of these types could lead the program down different execution paths depending on whether it is part of a 32-bit build or a 64-bit build.
For example, in a 32-bit build, a comparison between a ptrdiff_t and an unsigned int means that the compiler casts the ptrdiff_t to an unsigned int and so a negative value becomes a high positive value — an integer overflow that then leads to an unexpected path in the program being executed, or an access violation. But in a 64-bit build, the compiler upcasts the unsigned int to a signed 64-bit type, meaning there is no integer overflow and the expected path in the program is executed.
How an integer overflow leads to a buffer overflow
The principal manner in which an integer overflow vulnerability can be exploited is by circumventing any checks that limit the length of data to be stored in a buffer so as to induce a buffer overflow. This opens the door to the vast array of buffer overflow exploitation techniques that lead to further problems like escalation of privilege and execution of arbitrary code.
Let’s consider the following contrived example:
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
int MAX_BUFFER_LENGTH = 11; // [1]
char* initializeBuffer () {
char* buffer = (char*) malloc(MAX_BUFFER_LENGTH * sizeof(char));
if (buffer == NULL) {
printf("Could not allocate memory on the heap\n");
}
return buffer;
}
int main(void) {
signed int buffer_length;
char* source_buffer = "0123456789"; // Arbitrary test data
char* destination_buffer = NULL;
buffer_length = -1; // Hypothetical attacker-controlled variable
printf("buffer_length as a signed int is %d and implicitly cast to an unsigned int is %u\n", buffer_length, buffer_length);
// [2] Faulty size check
if (buffer_length > MAX_BUFFER_LENGTH) {
printf("Integer overflow detected\n");
}
else {
destination_buffer = initializeBuffer();
// [3] Potential buffer overflow due to integer overflow
strncpy(destination_buffer, source_buffer, buffer_length);
destination_buffer[buffer_length] = '\0';
printf("Destination buffer contents: %s\n", destination_buffer);
}
free(destination_buffer);
return 0;
}Not accustomed to C? Run this code right in your browser with a notebook in Google Colab.
At [2], there is no check for negative values of buffer_length meaning that it passes the check. Furthermore, the MAX_BUFFER_LENGTH is a signed int, but it should have been declared at [1] as an unsigned integer type because negative values should never be used when assigning buffer lengths. As an unsigned integer type, the compiler would have implicitly cast the buffer_length to an unsigned int at the check at [2] leading to detection of the integer overflow.
But with the −1 stored in buffer_length slipping past the check and the compiler implicitly casting it as an unsigned int in the initializeBuffer function at [3] instead, it overflows to a high positive value of around 4 billion, quite beyond the maximum expected buffer length of 11.
This integer overflow then leads directly to a buffer overflow because strncpy attempts to make a copy of around 4GB of data from the source buffer into the destination buffer. Thus, even though an attempt is made to prevent a buffer overflow with the size check at [2], the check is made incorrectly and an integer overflow occurs that leads directly to a buffer overflow.
When handling casts between signed and unsigned integer types, it’s not enough to make a size check for a value that is greater than the expected maximum value. It’s also critical to check for a value that is less than the expected minimum value:
// [2] Corrected size check
if (buffer_length < 0 || buffer_length > MAX_BUFFER_LENGTH) {Rules of thumb
Various strategies can be employed to check for and handle possible integer overflows in your code, some of which have a trade-off in portability vs. speed. Without considering those here, keep in mind at least the following guidelines:
- Prefer using unsigned integer types whenever possible. Remember, there is no sense in using a signed integer type to allocate memory because a negative value is never valid in this situation.
- Review and test your code by writing out all casts explicitly to see more easily where implicit casts might cause integer overflows.
- Turn on any options available in your compilers that can help identify certain types of integer overflows. For example, the GCC compiler has an -ftrapv option that checks for signed integer overflows.
Integer overflows are not a problem that is going to disappear anytime soon. Indeed, there are many older Unix-like systems that have a similar bug to Y2K22 “scheduled” to appear in 2038, which is hence called Y2K38. Before 64-bit systems were commonplace, 32-bit systems ruled the land, meaning that Unix time was stored as a signed 32-bit integer. Because Unix time begins counting seconds from 00:00:00 UTC on January 1, 1970, 32-bit time can only take us a few hours into January 19, 2038 before wrapping around. Luckily, knowing of the problem ahead of time allows us to prepare and update many vulnerable systems before we roll around the circle and slide back to 1901.



